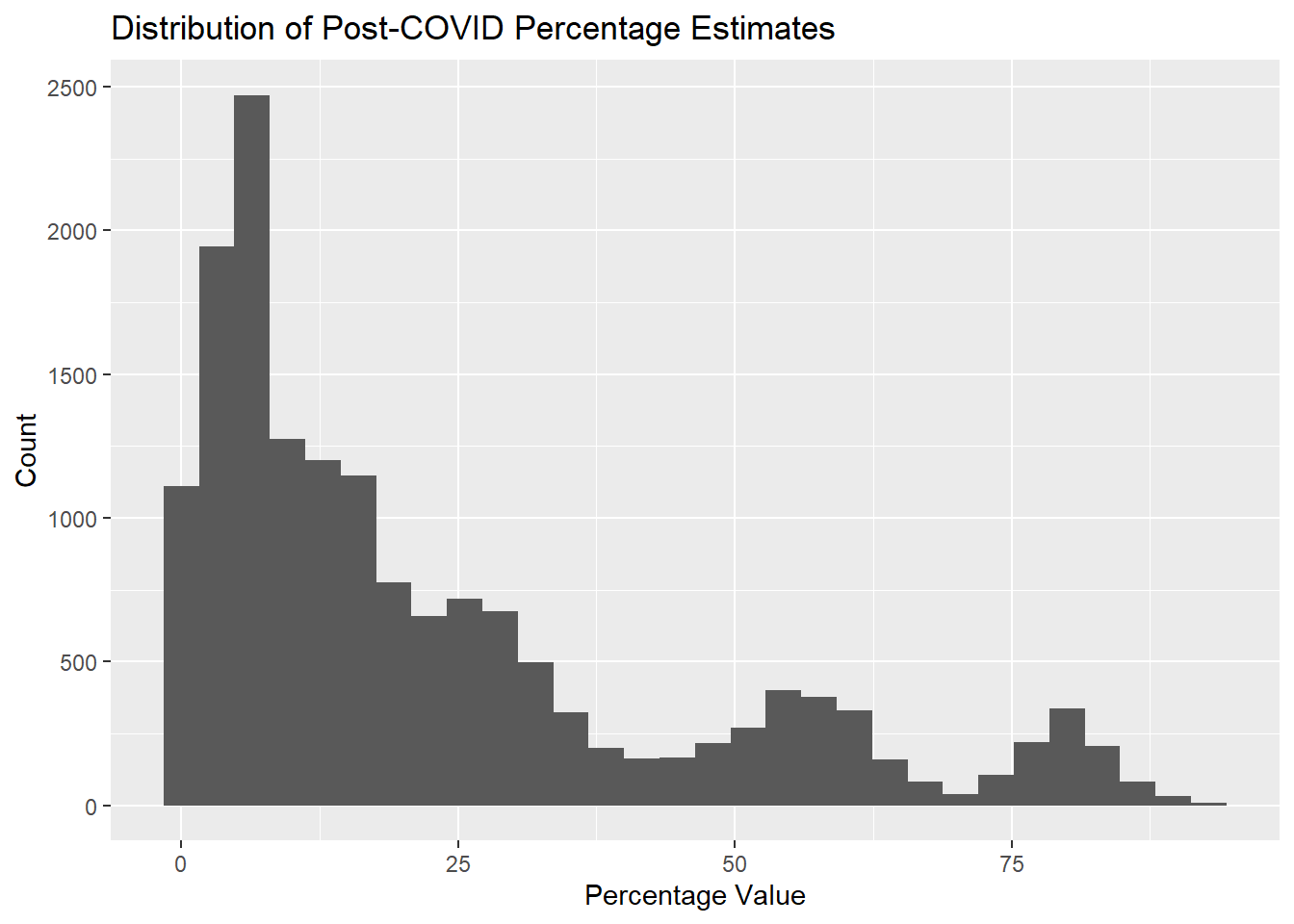
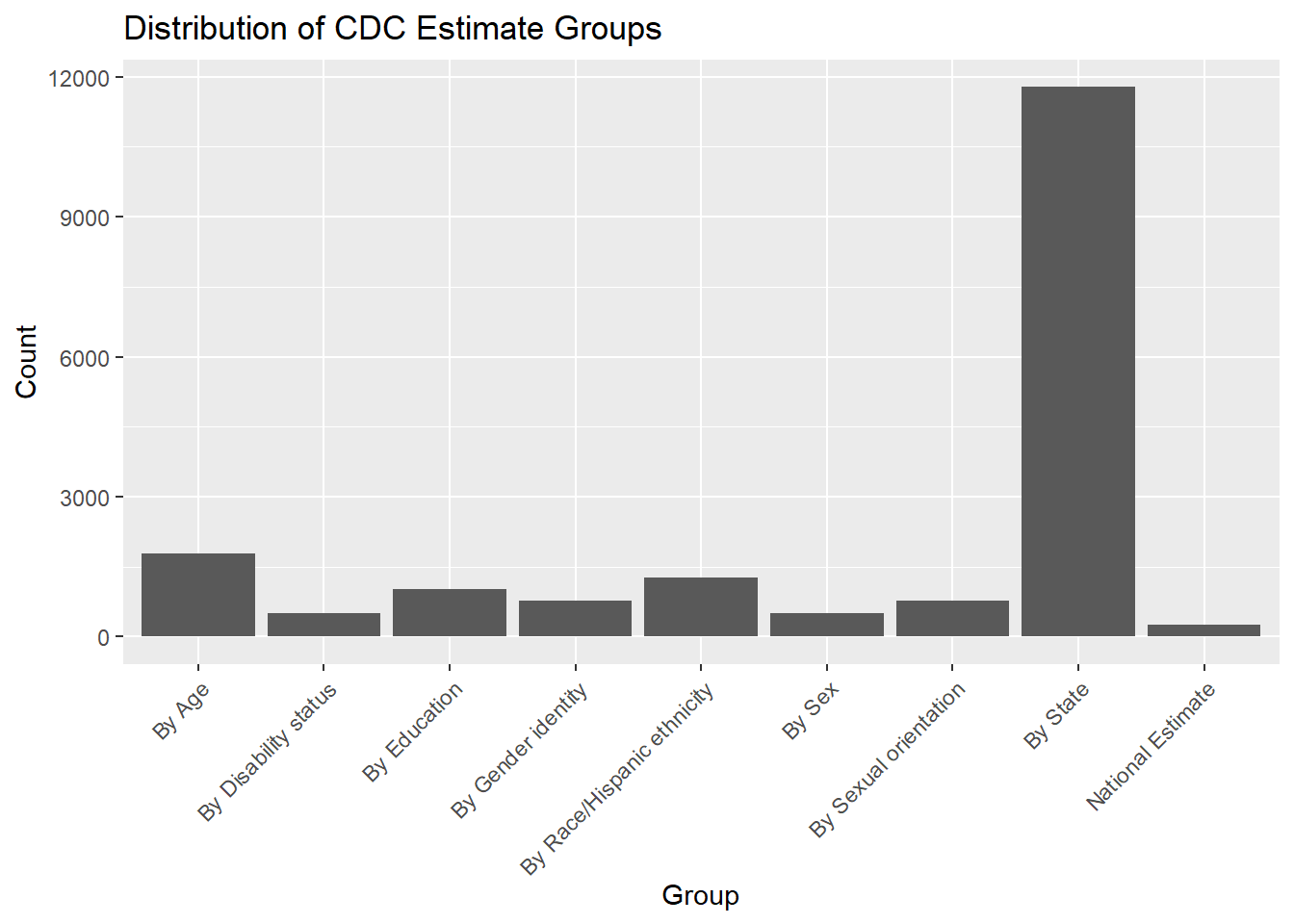
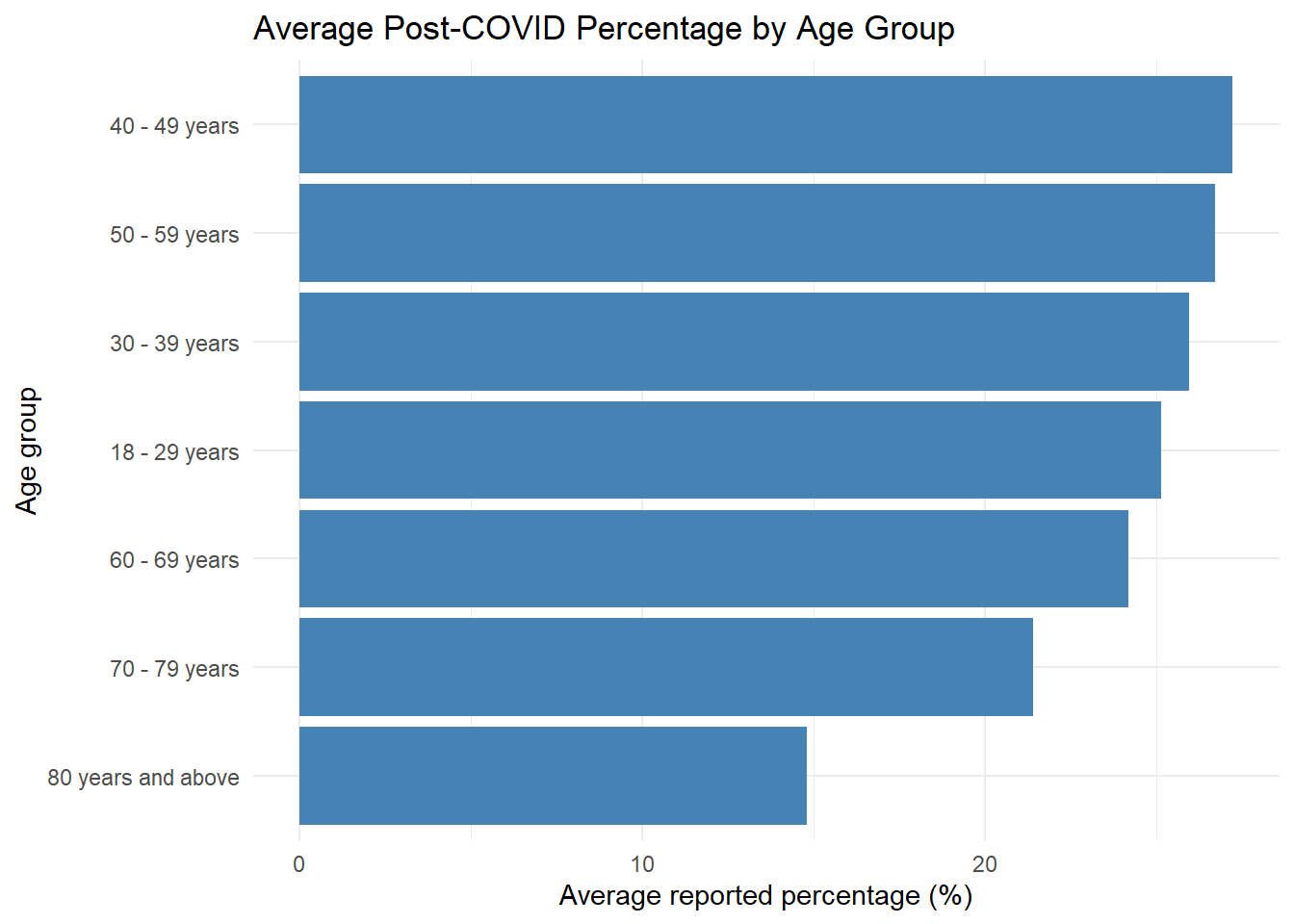
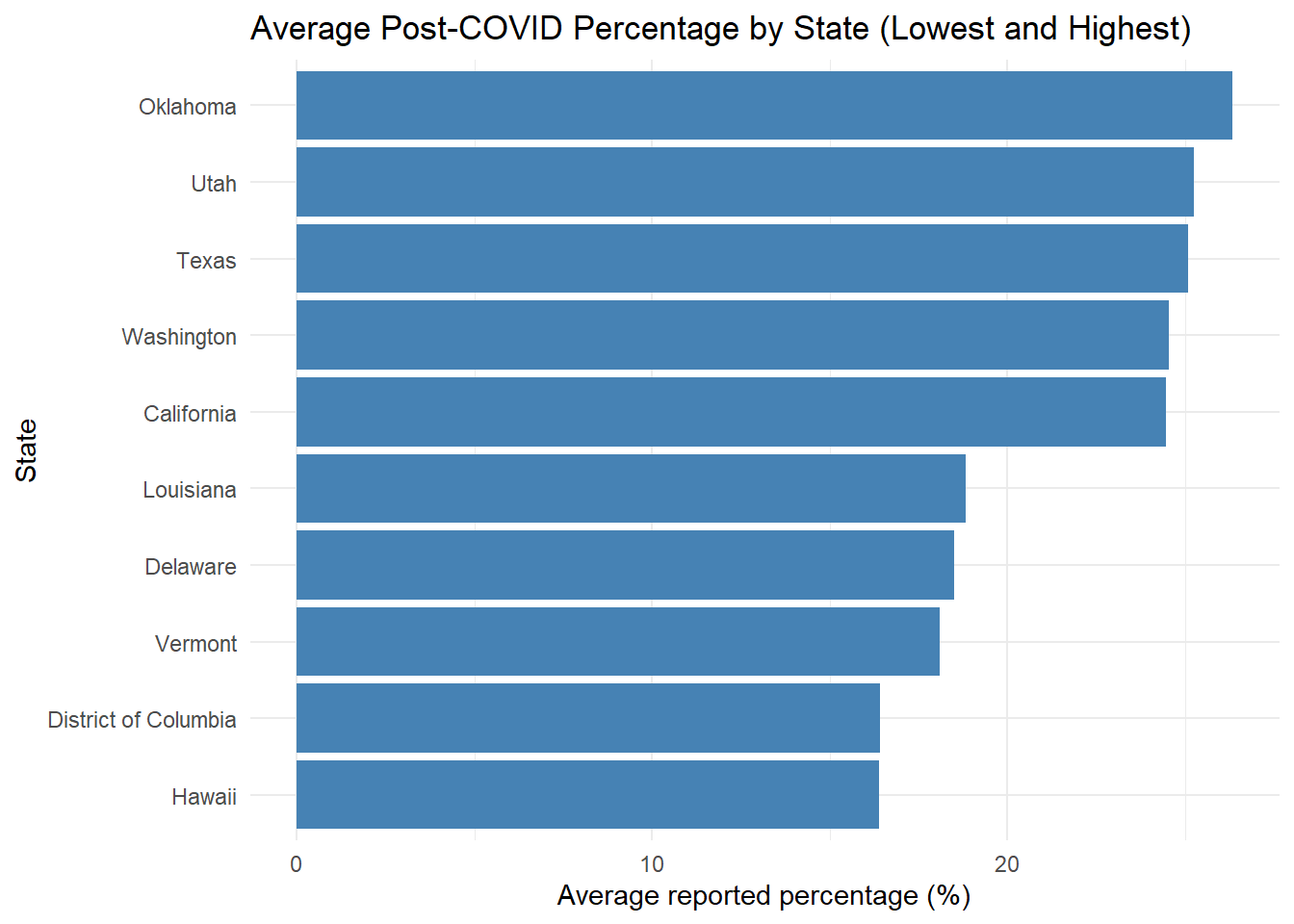
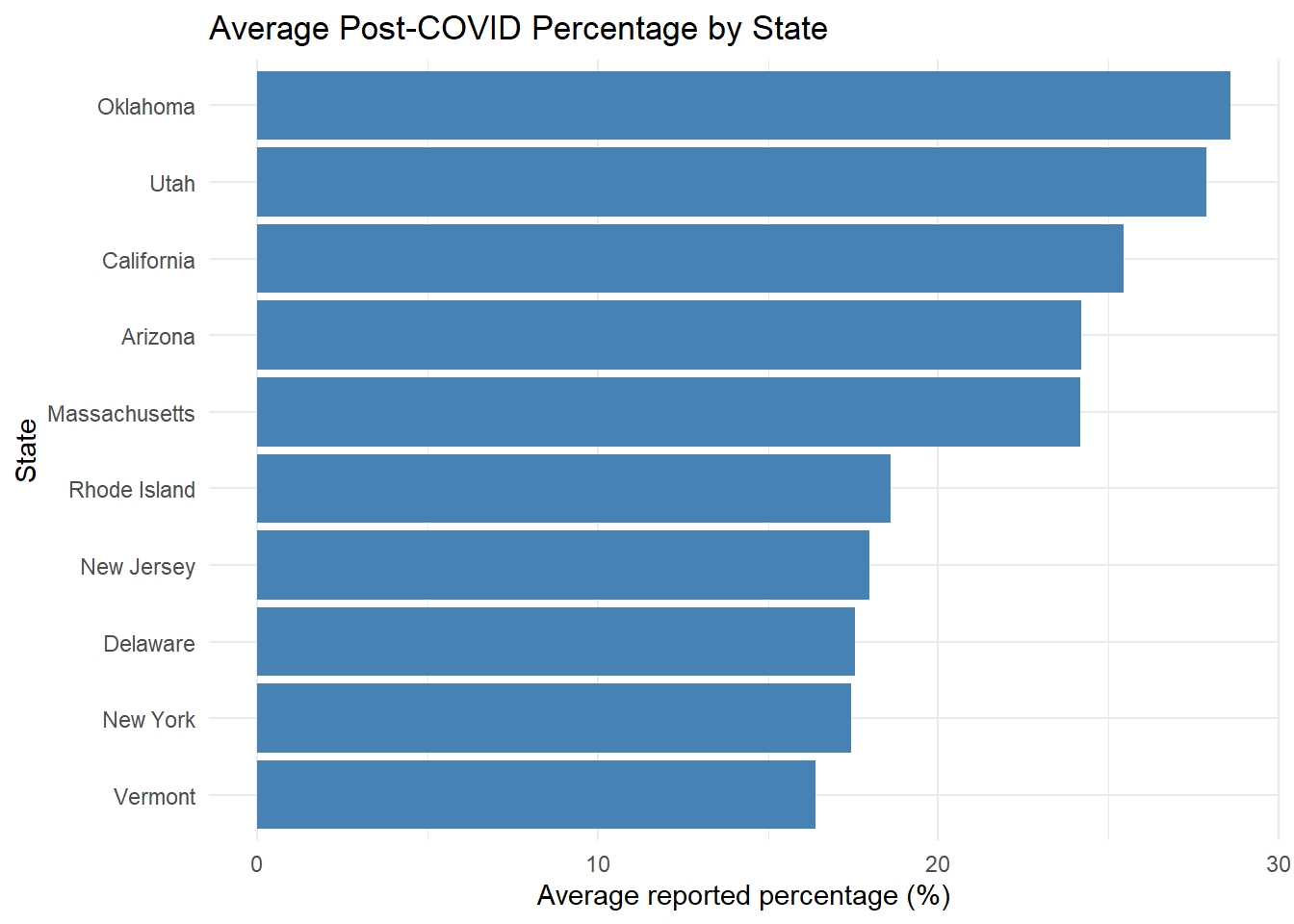
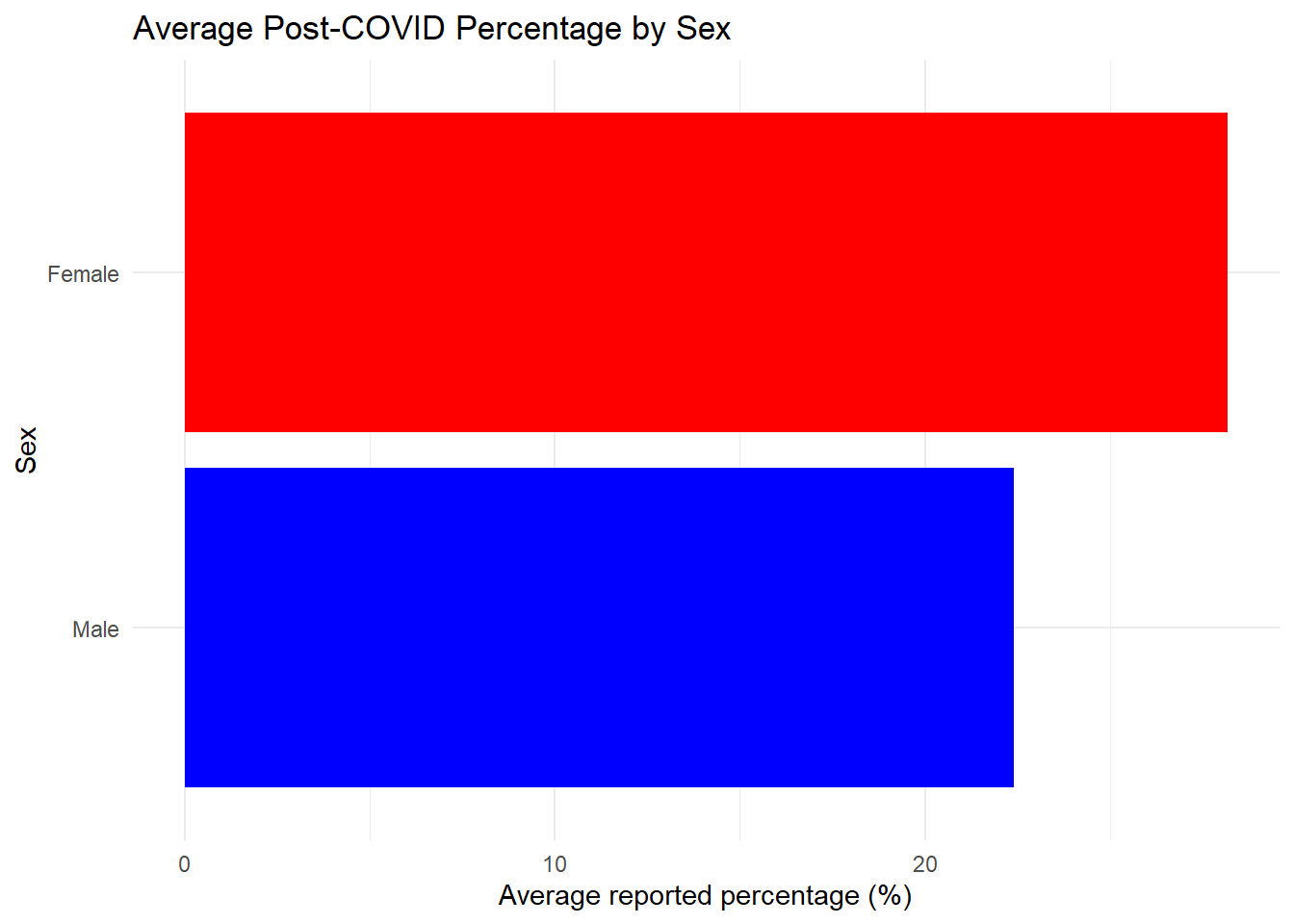
Rows: 18639 Columns: 16
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (9): Indicator, Group, State, Subgroup, Time Period Label, Time Period S...
dbl (7): Phase, Time Period, Value, LowCI, HighCI, Quartile number, Suppress...
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
Rows: 18,639
Columns: 16
$ Indicator <chr> "Ever experienced long COVID, as a percentage…
$ Group <chr> "National Estimate", "By Age", "By Age", "By …
$ State <chr> "United States", "United States", "United Sta…
$ Subgroup <chr> "United States", "18 - 29 years", "30 - 39 ye…
$ Phase <dbl> 3.5, 3.5, 3.5, 3.5, 3.5, 3.5, 3.5, 3.5, 3.5, …
$ `Time Period` <dbl> 46, 46, 46, 46, 46, 46, 46, 46, 46, 46, 46, 4…
$ `Time Period Label` <chr> "Jun 1 - Jun 13, 2022", "Jun 1 - Jun 13, 2022…
$ `Time Period Start Date` <chr> "06/01/2022", "06/01/2022", "06/01/2022", "06…
$ `Time Period End Date` <chr> "06/13/2022", "06/13/2022", "06/13/2022", "06…
$ Value <dbl> 14.0, 17.8, 15.2, 16.9, 15.3, 10.9, 7.1, 4.2,…
$ LowCI <dbl> 13.5, 15.9, 14.1, 15.7, 14.1, 9.8, 5.9, 3.4, …
$ HighCI <dbl> 14.5, 19.8, 16.2, 18.3, 16.7, 12.0, 8.5, 5.3,…
$ `Confidence Interval` <chr> "13.5 - 14.5", "15.9 - 19.8", "14.1 - 16.2", …
$ `Quartile range` <chr> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
$ `Quartile number` <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
$ `Suppression Flag` <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…